MOSS (Measure of Software Similarity) is a very effective plagiarism detection system that is commonly used by computer science professors across the country. Most students know that it’s nearly impossible to get away with plagiarism when MOSS is used, but not many know of how MOSS works or why it’s so effective. In this post, I will give an overview of copy-detection, document fingerprinting, and explain the winnowing algorithm used by MOSS. Then I will discuss the implementation and use of MOSS, and my experience evaluating the effectiveness of an OCaMOSS, an OCaml implementation of MOSS (my final project for CS 3110).
Note: This post is based on Winnowing: Local Algorithms for Document Fingerprinting and the writeup for OCaMOSS. All figures are borrowed from those 2 papers.
MOSS is a type of copy-detection algorithm. Given a set of documents, a copy-detection algorithm identifies pairs of documents which are likely to have copied from each other. There are three properties that are required in effective copy-detection algorithms:
- Whitespace insensitivity - The algorithm must be able to ignore meaningless syntax like whitespace. For source-code plagiarism detection, the algorithm must also be unaffected by renaming variables.
- Noise Suppression - The discovered matches need to be long enough to be significant and interesting - for example, flagging a single matching word would not be a meaningful result.
- Position independence - The position of the matching segments in each document should not affect the number of matches discovered. This means that reordering large blocks like functions should have no effect on the algorithm.
Beyond these main requirements, other desired features include fast runtime when operating on long documents or large quantities of documents, and a low rate of false-positives (which noise insensitivity helps reduce).
In order for these properties to hold, a naive copy-detection algorithm would need to compare every substring of every document with every substring of every other document. This is very computationally expensive, so the creators of MOSS use a different technique known as document fingerprinting. Document fingerprinting is a technique for copy-detection that avoids naively comparing substrings. Instead, a set of hashes (a fingerprint) is precomputed for each document, and comparisons are made between the fingerprints of each document instead, which drastically reduces the total number of comparisons.
The process of applying document fingerprinting in plagiarism detection can be described in four steps.
- Preprocess the document to remove irrelevant features like whitespace and identifiers.
- Generate a sequence of hashes of the k-grams of the preprocessed document (the selection of k varies depending on the specific technique).
- Select a subset of hashes to use as document’s fingerprints.
- Pairs of documents with a high number of matching fingerprints are flagged for review.
The third step in document fingerprinting is interesting because which fingerprints are selected in each document will directly affect the number of matches discovered. MOSS uses a fingerprint selection algorithm called winnowing. At a high level, the algorithm applies sliding window of size w to the list of hashes. At each step, the algorithm records the rightmost minimum value in the window (if it has not been recorded already). When the window reaches the end of the sequence of hashes, the recorded set of hashes is taken as the fingerprints of the document.
Below is an example of document fingerprinting on a short example text, with the winnowing algorithm highlighted in steps d-f.

The winnowing algorithm results in fingerprints with several very useful properties (for detailed proofs, please see the winnowing paper). Using k-grams and a window size w, the following properties will hold:
- Noise insensitivity: No matches shorter than k are detected; the algorithm hashes substrings of length k, which means matching segments must be at least length k to be hashed to the same value.
- Even distribution of hashes: Winnowing is guaranteed to select at least one hash per window-length; by the time the window has shifted one window length, the previous lowest hash must have moved out of the window and thus the algorithm is forced to select a new lowest hash from within the current window. This property is useful because it ensures that no part of the document will be omitted from the set of fingerprints.
- Guaranteed detection of long matches: the above two properties ensure that matches of at least length w + k - 1 always detected.
In practice, MOSS uses a more robust winnowing algorithm that selects fewer fingerprints, which will not be discussed here but is described in slightly more detail in the original paper. There are two main components to MOSS. The first is a front-end that is language-specific that prepares each document by removing whitespace, identifiers, and filtering keywords specific to that language. The document is then input into the fingerprinting engine, which operates with no knowledge of the type of the original documents. Fingerprints are tagged with their position in the original source code in order to display matching sections to the user. Additionally, instructors can specify a document of boilerplate code in the corpus, and MOSS will ignore hashes that match those of the boilerplate. The authors report that in practice MOSS has been effective at both detecting plagiarism and reducing plagiarism in classes, and that there have been no false-positives caused by the algorithm itself.
In spring of 2018 we built an implementation the winnowing algorithm in OCaml and used it in a plagiarism detection system called OCaMOSS. We found that the core algorithm behind MOSS was astonishingly simple to implement: the pseudocode for the winnowing algorithm is no more than 50 lines long, and our entire implementation was only about 800 lines of code. We performed tests on several datasets of source code plagiarism and tested for both speed and correctness. Extending the system to support a new programming language was as simple as adding a new config file that defines that language’s keywords and comment syntax. Below I have included results of testing OCaMOSS on the MiniFactorial corpus created by NordicWay. The test corpus contains 4 types of plagiarism:
- type 1 refers to changing whitespace, layout, and comments
- type 2 refers to changing types, identifiers, and literals
- type 3 refers to reordering, adding, or removing statements
- type 4 refers to refactoring the code to use different syntactic variants
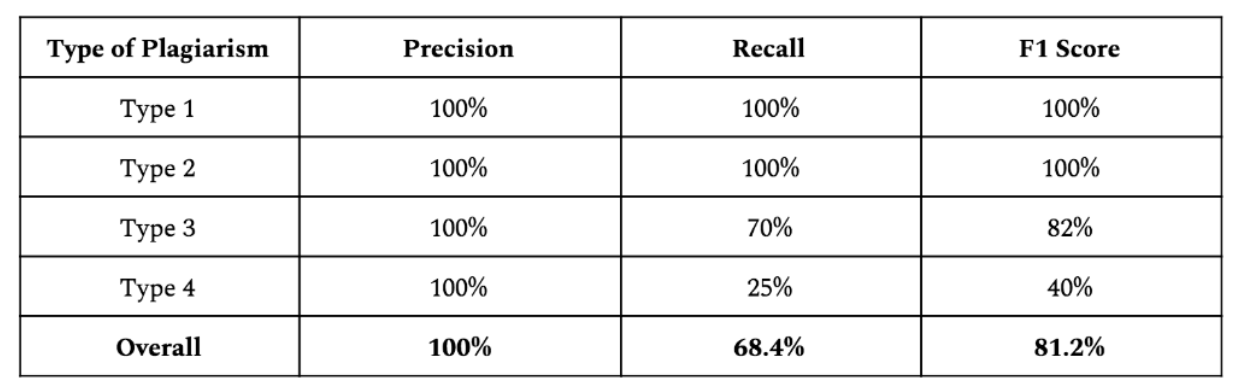
Our system achieved the goal of having no false-positives, while still maintaining a high recall among most of the classes. The misclassification of some type-3 examples is probably due to the nature of the test corpus (programs are extremely short, and thus certain reorderings will affect every hash that is generated from the document). The misclassification of type-4 examples is due to the nature of type-4 plagiarism: if someone refactors the copied code heavily, the code can become sufficiently different structurally that we do not flag it to avoid the risk of generating false-positives.
As a former TA in college, I can say that in practice it’s very hard (and generally not worth even trying) to fool MOSS for academic assignments, because:
- The more code there is in each project, the better this system performs. The tests above were conducted on snippets of less than 100 lines of code, and most coding projects will be much longer.
- MOSS has more sophisticated preprocessing and matching techniques beyond the simple algorithm implemented in OCaMOSS.
- Obfuscating plagiarized code is time consuming and results in weird structures/artifacts that are pretty easy to catch the moment someone actually reads the code.
Don’t bother trying to fool MOSS, it’s not worth it and it probably won’t work. Just take the L and move on, one assignment isn’t a huge deal. – Unknown
With all the hype around machine learning these days, I think it’s nice to see that a simple and elegant algorithm performs so well at this task. Personally, I think the biggest benefit of MOSS and the winnowing algorithm is that its simplicity makes it very interpretable - matching fingerprints can be mapped exactly to the original source code, allowing instructors to understand the nature of the cheating and identify if the system made any mistakes. With deep learning models, it becomes nearly impossible to have the same amount of transparency and interpretability. To me, that’s a major flaw because no one will trust a system if they cannot understand where the result came from. MOSS’s simplicity, effectiveness, and interpretability combine to make it a very useful and reliable system to detect and deter plagiarism in computer science courses.